
< Terug naar nieuws
Het vermogen van NLP-modellen om goed te generaliseren is een van de belangrijkste desiderata van het huidige NLP-onderzoek. Er is momenteel echter geen consensus over wat 'goede generalisatie' inhoudt en hoe het moet worden geëvalueerd. De ruwe definitie is het vermogen om representaties, kennis en strategieën uit eerdere ervaringen succesvol over te dragen naar nieuwe ervaringen. Het kan dus bijvoorbeeld betekenen dat een model in staat is om voorspellingen op basis van een bepaalde dataset op een robuuste, betrouwbare en eerlijke manier toe te passen op een nieuwe dataset. Maar verschillende onderzoekers gebruiken verschillende definities. Ook zijn er momenteel geen gemeenschappelijke normen om generalisatie te evalueren. Als gevolg hiervan worden nieuw voorgestelde NLP-modellen meestal niet systematisch getest op hun vermogen om te generaliseren.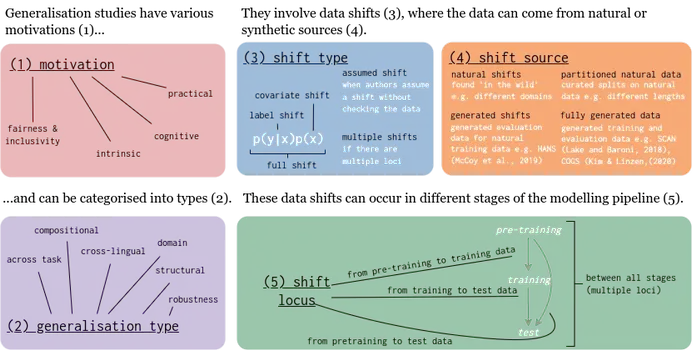
GenBench
Vijf assen
Dit artikel is gepubliceerd op de website van de Universiteit van Amsterdam.







10 november 2023
Nieuwe taxonomie wil generalisatie onderzoek in NLP verbeteren
Natural Language Processing - het deelgebied van de computerwetenschap dat zich bezighoudt met het vermogen van computers om menselijke taal te 'begrijpen' en te 'genereren' - heeft de afgelopen tien jaar een enorme vlucht genomen.
Het grote publiek is inmiddels op de hoogte van NLP door de opkomst van tools als klantenservicechatbots op websites en ChatGPT. Ondertussen gaat het onderzoek naar hoe je NLP-modellen verder kunt verbeteren door. In een artikel in Nature Machine Intelligence biedt een internationaal team van wetenschappers, waaronder onderzoekers van de Universiteit van Amsterdam, een raamwerk om een aspect van NLP-modellen, generalisatie genaamd, te verbeteren.
Het vermogen van NLP-modellen om goed te generaliseren is een van de belangrijkste desiderata van het huidige NLP-onderzoek. Er is momenteel echter geen consensus over wat 'goede generalisatie' inhoudt en hoe het moet worden geëvalueerd. De ruwe definitie is het vermogen om representaties, kennis en strategieën uit eerdere ervaringen succesvol over te dragen naar nieuwe ervaringen. Het kan dus bijvoorbeeld betekenen dat een model in staat is om voorspellingen op basis van een bepaalde dataset op een robuuste, betrouwbare en eerlijke manier toe te passen op een nieuwe dataset. Maar verschillende onderzoekers gebruiken verschillende definities. Ook zijn er momenteel geen gemeenschappelijke normen om generalisatie te evalueren. Als gevolg hiervan worden nieuw voorgestelde NLP-modellen meestal niet systematisch getest op hun vermogen om te generaliseren.
Deze infographic toont de vijf assen van de taxonomie. Credit: GenBench/UvA
GenBench
Om dit probleem te verhelpen heeft een internationaal team van onderzoekers, waaronder meerdere onderzoekers van het Institute for Logic, Language and Computation (ILLC) van de Universiteit van Amsterdam, nu een analyse gepubliceerd in Nature Machine Intelligence. In het artikel presenteren ze een taxonomie voor het karakteriseren en begrijpen van generalisatieonderzoek in NLP. De publicatie is het eerste resultaat van het grotere project GenBench, geleid door UvA-ILLC alumna Dieuwke Hupkes.
Vijf assen
Hoofdauteur Mario Giulianelli (UvA-ILLC) licht toe: 'De taxonomie die we in onze Analyse voorstellen is gebaseerd op een uitgebreid literatuuronderzoek. We hebben vijf assen geïdentificeerd waarlangs generalisatiestudies kunnen verschillen: hun belangrijkste motivatie, het type generalisatie dat ze willen oplossen, het type dataverschuiving dat ze beschouwen, de bron waardoor deze dataverschuiving is ontstaan en de locatie van de verschuiving binnen de moderne NLP-modelleerpijplijn. Vervolgens hebben we onze taxonomie gebruikt om meer dan 700 experimenten te classificeren. We hebben deze resultaten gebruikt om een diepgaande analyse te presenteren die de huidige staat van generalisatieonderzoek in NLP in kaart brengt en we doen aanbevelingen voor welke gebieden in de toekomst aandacht verdienen.
Project website
NLP-onderzoekers die geïnteresseerd zijn in het onderwerp generalisatie kunnen ook de GenBench website bezoeken. De website biedt meerdere tools voor degenen die geïnteresseerd zijn in het verkennen en beter begrijpen van generalisatiestudies, waaronder een evoluerende enquête, visualisatietools en, binnenkort, een generalisatie leaderboard. De eerste GenBench workshop vindt plaats tijdens de EMNLP 2023 conferentie, op 6 december.
Dit artikel is gepubliceerd op de website van de Universiteit van Amsterdam.
Vergelijkbaar >
Vergelijkbare nieuwsitems
14 November 2024
De Amsterdamse Visie op AI: Een Realistische Blik op Kunstmatige Intelligentie
In het nieuwe beleid, De Amsterdamse Visie op AI, wordt beschreven hoe kunstmatige intelligentie (AI) een rol mag spelen in Amsterdam, en hoe deze technologie het leven in de stad mag beïnvloeden volgens de inwoners. Deze visie is tot stand gekomen na een maandenlang proces van gesprekken en dialoog, waarin een breed scala aan Amsterdammers – van festivalbezoekers tot schoolkinderen en van experts tot digibeten – hun mening gaven over de toekomst van AI in hun stad.
Lees meer >
14 November 2024
Interview: KPN Responsible AI Lab met Gianluigi Bardelloni en Eric Postma
ICAI's Interview featured deze keer Gianluigi Bardelloni en Eric Postma, zij praten over de ontwikkelingen in hun ICAI Lab.
Lees meer >
14 november
AI pilots TLC Science: Generatieve AI in wetenschappelijk onderwijs
De UvA is een nieuw project gestart waarbij het Teaching & Learning Centre Science onderzoekt hoe Generatieve AI, specifiek ChatGPT, kan bijdragen aan het verbeteren van academisch onderwijs. Binnen dit pilotprogramma aan de Faculteit der Natuurwetenschappen worden diverse toepassingen van GenAI in het hoger onderwijs getest en geëvalueerd.
Lees meer >