
< Back to news 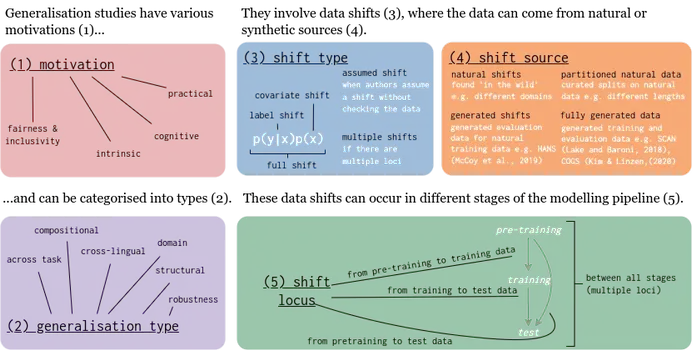
To help overcome this problem, an international team of researchers, including multiple researchers from the University of Amsterdam’s Institute for Logic, Language and Computation (ILLC), has now published an Analysis in Nature Machine Intelligence. In the paper, they present a taxonomy for characterizing and understanding generalization research in NLP. The publication is the first result of the larger project GenBench, led by UvA-ILLC alumna Dieuwke Hupkes.
Lead author Mario Giulianelli (UvA-ILLC) comments: ‘The taxonomy we propose in our Analysis is based on an extensive literature review. We identified five axes along which generalization studies can differ: their main motivation, the type of generalization they aim to solve, the type of data shift they consider, the source by which this data shift originated, and the locus of the shift within the modern NLP modelling pipeline. Next, we used our taxonomy to classify over 700 experiments. We used these results to present an in-depth analysis that maps out the current state of generalization research in NLP and we make recommendations for which areas deserve attention in the future.’
NLP researchers interested in the topic of generalization can also visit the GenBench website. The website offers multiple tools for those interested in exploring and better understanding generalization studies, including an evolving survey, visualization tools and, soon, a generalization leaderboard. The first GenBench workshop will take place at the EMNLP 2023 conference, on December 6th. 







10 November 2023
New taxonomy aims to improve generalization research in NLP
Natural Language Processing—the subfield of computer science concerned with giving computers the ability to ‘understand’ and ‘generate’ human language—has taken a huge flight in the past decade.
The general public now knows about NLP because of the rise of tools like customer service chatbots on websites and ChatGPT. Meanwhile, research into how to further improve NLP models continues. In a paper in Nature Machine Intelligence an international team of scientists, including researchers of the University of Amsterdam, provide a framework to improve an aspect of NLP models called generalization.
The ability for NLP models to generalize well is one of the main desiderata of current NLP research. However, there is currently no consensus as to what ‘good generalization’ entails and how it should be evaluated. The rough definition is the ability to successfully transfer representations, knowledge and strategies from past experience to new experiences. So it can for instance be taken to mean that a model is able to apply predictions based on a certain data set to a new data set in a robust, reliable and fair way. But different researchers use different definitions. Also, there are currently no common standards to evaluate generalization. As a consequence, newly proposed NLP models are usually not systematically tested for their ability to generalize.
This infographic shows the five axes of the taxonomy. Credit: GenBench/UvA
GenBench
To help overcome this problem, an international team of researchers, including multiple researchers from the University of Amsterdam’s Institute for Logic, Language and Computation (ILLC), has now published an Analysis in Nature Machine Intelligence. In the paper, they present a taxonomy for characterizing and understanding generalization research in NLP. The publication is the first result of the larger project GenBench, led by UvA-ILLC alumna Dieuwke Hupkes.
Five axes
Lead author Mario Giulianelli (UvA-ILLC) comments: ‘The taxonomy we propose in our Analysis is based on an extensive literature review. We identified five axes along which generalization studies can differ: their main motivation, the type of generalization they aim to solve, the type of data shift they consider, the source by which this data shift originated, and the locus of the shift within the modern NLP modelling pipeline. Next, we used our taxonomy to classify over 700 experiments. We used these results to present an in-depth analysis that maps out the current state of generalization research in NLP and we make recommendations for which areas deserve attention in the future.’
Project website
NLP researchers interested in the topic of generalization can also visit the GenBench website. The website offers multiple tools for those interested in exploring and better understanding generalization studies, including an evolving survey, visualization tools and, soon, a generalization leaderboard. The first GenBench workshop will take place at the EMNLP 2023 conference, on December 6th.
This article was published on the website of the University of Amsterdam.
Vergelijkbaar >
Similar news items
April 16, 2025
AWS: Dutch businesses are adopting AI faster than the European average
New research from AWS shows that Dutch businesses are rapidly adopting AI—at a rate of one new implementation every four minutes, well ahead of the European average.
read more >
April 16, 2025
Submit your nomination for the Dutch Applied AI Award 2025
Do you know or develop an innovative AI application? Submit it now for the 2025 Dutch Applied AI Award, presented at the Computable Awards.
read more >
April 16, 2025
UK government tests AI to predict murders
The UK government is developing an AI system that could predict who is most likely to commit a serious crime. Critics call the project dangerous and discriminatory.
read more >